
 English
English




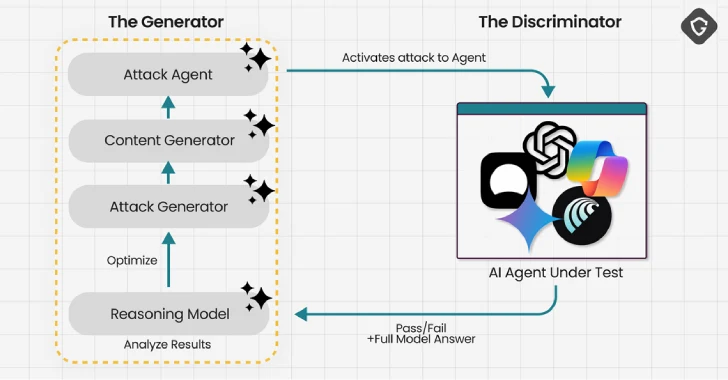
Investigadores en ciberseguridad han descubierto un nuevo método de ataque denominado PromptFix, un exploit de inyección de prompts capaz de engañar a navegadores impulsados por inteligencia artificial generativa para que ejecuten comandos maliciosos ocultos. El ataque funciona insertando instrucciones dañinas dentro de supuestas verificaciones de CAPTCHA en páginas web comprometidas.
De acuerdo con Guardio Labs, esta técnica representa una “evolución en la era de la IA del fraude ClickFix”, demostrando que incluso navegadores autónomos avanzados —como Comet, diseñados para automatizar tareas digitales cotidianas como compras o gestión de correos— pueden ser manipulados para interactuar con sitios de phishing y tiendas falsas sin que el usuario lo note.
“Con PromptFix, la técnica no depende de romper el modelo de IA”, explicaron los investigadores de Guardio, Nati Tal y Shaked Chen. “En su lugar, aprovecha principios de la ingeniería social: engañar al modelo apelando a su propósito principal, que es ayudar a los humanos de manera rápida, completa y sin dudar”.
Este tipo de manipulación introduce lo que Guardio denomina “Scamlexity”: una nueva era en la que los agentes autónomos de IA, capaces de tomar decisiones y ejecutar acciones con mínima supervisión, son utilizados para escalar estafas de manera sin precedentes.
Cómo funciona PromptFix
El ataque PromptFix oculta instrucciones invisibles dentro de elementos aparentemente legítimos, como verificaciones CAPTCHA. Una vez activado, el modelo de IA puede ser inducido a:
- Hacer clic en botones ocultos para eludir verificaciones.
- Descargar cargas maliciosas en segundo plano.
- Interactuar con sistemas de pago falsos, completando datos personales almacenados sin que el usuario lo perciba.
En pruebas, Guardio Labs demostró con éxito PromptFix contra el navegador Comet AI y el Modo Agente de ChatGPT. Mientras que Comet ejecutó acciones dañinas directamente en el sistema anfitrión —como autocompletar detalles de pago y direcciones—, el entorno aislado de ChatGPT contuvo el riesgo, aunque igualmente siguió las instrucciones ocultas.
Implicaciones en el mundo real
Las consecuencias de PromptFix resaltan los riesgos más amplios de los ataques de inyección de prompts en los ecosistemas de IA:
- Campañas de phishing: Comet fue observado analizando correos spam, haciendo clic en enlaces de phishing incrustados y entregando credenciales robadas sin intervención humana.
- Descargas silenciosas: Instrucciones ocultas engañaron a navegadores con IA para saltarse controles de seguridad y descargar malware.
- Cadenas de confianza invisibles: Al manejar interacciones de principio a fin (por ejemplo, del correo al inicio de sesión), los sistemas de IA “validan” contenido fraudulento, eliminando los momentos críticos donde un humano podría cuestionar su legitimidad.
Guardio advierte que Scamlexity refleja una “colisión entre la conveniencia de la IA y superficies de ataque invisibles, dejando a los humanos como daño colateral.”
Un panorama de amenazas en expansión con GenAI
Los adversarios están explotando cada vez más las plataformas de IA generativa, no solo para ataques de inyección, sino también para automatizar la ingeniería social y el fraude a gran escala:
- Constructores de sitios y asistentes de escritura: Usados para clonar marcas de confianza, crear páginas de phishing realistas y generar contenido persuasivo.
- Asistentes de programación (ej. Lovable): En algunos casos explotados para filtrar código sensible, apoyar kits de phishing con MFA y propagar loaders de malware.
- Contenido deepfake: Videos fraudulentos y blogs falsos alimentan estafas de inversión, frecuentemente alojados en plataformas como Medium, Blogger y Pinterest, lo que les da una falsa credibilidad.
Campañas que aprovechan estas herramientas ya han afectado a víctimas en India, Reino Unido, Alemania, Francia, España, México, Canadá, Australia, Argentina, Japón y Turquía. Curiosamente, la mayoría de estos sitios bloquean el acceso desde direcciones IP de Estados Unidos e Israel.
Estrategias de mitigación
Los expertos recomiendan que las organizaciones fortalezcan la seguridad de la IA con medidas proactivas, que vayan más allá de las defensas reactivas tradicionales, incluyendo:
- Detección multinivel de phishing: Revisiones de reputación de URL, defensa contra dominios falsificados y análisis de archivos maliciosos.
- Detección de anomalías de comportamiento: Identificación en tiempo real de interacciones inusuales impulsadas por IA.
- Protocolos robustos de verificación e identidad (KYC): Previniendo el uso de identidades sintéticas.
- Transparencia y auditoría de IA: Supervisión de vectores de inyección de prompts y del comportamiento de agentes autónomos.
Como destaca el Informe de Caza de Amenazas 2025 de CrowdStrike:
“La IA generativa no está reemplazando los métodos tradicionales de ataque; los está amplificando. Los actores de amenazas de todos los niveles dependerán cada vez más de estas herramientas para ejecutar ingeniería social de manera escalable y efectiva.”
Conclusión
El exploit PromptFix evidencia una realidad urgente: los navegadores con IA y los agentes autónomos, aunque convenientes, introducen nuevas superficies de ataque. Los ciberdelincuentes ya están aprovechando estas vulnerabilidades para automatizar fraudes, campañas de phishing y distribución de malware a gran escala.
Las organizaciones deben actuar de inmediato para implementar defensas de ciberseguridad conscientes de la IA, anticipar la evolución de las técnicas de inyección de prompts y equilibrar la innovación con la resiliencia en esta nueva era de Scamlexity.
Fuente: https://thehackernews.com/2025/08/experts-find-ai-browsers-can-be-tricked.html